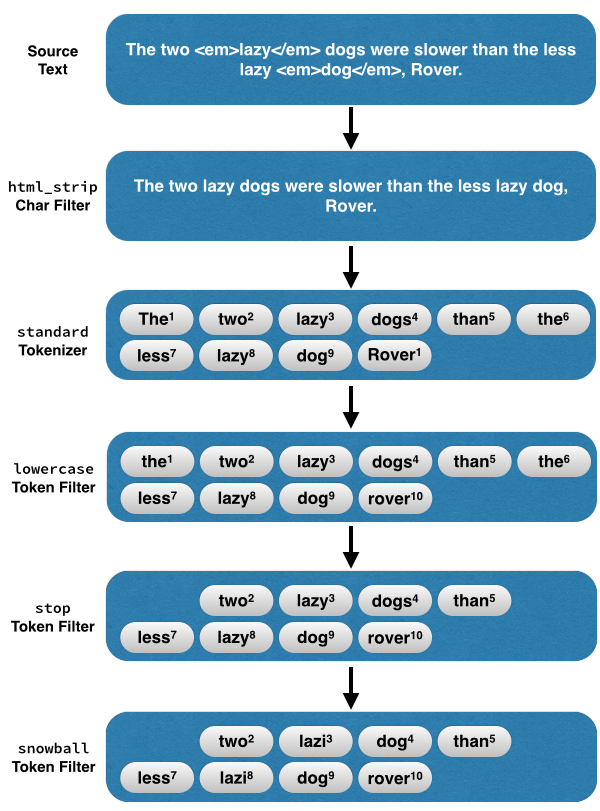
前面的文章有提到 Elasticsearch 因為是使用反向索引,所以會在建立 Document 時將句子拆開來以建立反向索引。而這個拆分的過程就是由分析器所執行的,分析器主要由三個部分所組成 :
Character Filters (字符過濾器)
Tokenizer (分詞器)
Token Filter (單詞過濾器)
下面我們就來了解分析器是如何運作的。
分析器的工作流程
分析器就像流水線一樣,字串經過一關一關的處理,最後得到單詞。如下 :
Character Filters (字符過濾器)
字符過濾器用於對字串先進行預處理,也就是會先整理這些字串。例如,去除 html 標籤或是將 & 轉換成 and。
Tokenizer (分詞器)
分詞器會將處理過的字串進行分詞,也就是將字串拆分成單詞。
Token Filter (單詞過濾器)
經過分詞後,單詞在經過單詞過濾器時可能會被改變,例如,大寫換成小寫、刪除無用的單詞 (a、and、the 等等) 或是新增單詞 (harmful、detrimental 這種同義詞)。
範例
內建的分析器
Standard Analyzer (標準分析器)
標準分析器 是 Elasticsearch 默認使用的分析器,他會根據 Unicode 所定義的單詞邊界 來劃分字串,並刪除大部分的標點符號。最後再將所有單詞轉換成小寫。標準分析器也可以指定要過濾的字(Stop Words)。
範例 3. Semi-formal, as the name implies, is slightly more relaxed.
經過標準分析器後會產生 :3、semi、formal、as、the、name、implies、is、slightly、more、relaxed
Simple Analyzer (簡單分析器)
簡單分析器會在任何不是字母的地方劃分單詞,再將單詞轉成小寫。
範例 semi、formal、as、the、name、implies、is、slightly、more、relaxed
可以發現數字 3 不見了,因為他不是字母。
Whitespace Analyzer (空格分析器)
空格分析器會在空格的地方劃分單詞。
範例 3.、Semi-formal,、as、the、name、implies,、is、slightly、more、relaxed.
可以發現 semi-formal 因為中間不是空格,所以不會被劃分成兩個單詞。
Stop Analyzer (停用詞分析器)
停用詞分析器基本上有和簡單分析器一樣的功能。此外他還會過濾掉停用詞,預設是英文的修飾詞,例如, a、the、is 等等。
同樣使用標準分析器範例所輸入的內容,經過停用詞分析器後會產生 :semi、formal、name、implies、slightly、relaxed
可以發現有許多單詞已經被過濾掉了。除了預設的停用詞過濾,也可以自己指定要過濾的單詞。
Keyword Analyzer (關鍵字分析器)
關鍵字分析器不會進行分詞,會直接將輸入當作一個單詞。也就是說以標準分析器的範例輸入內容來說,3. Semi-formal, as the name implies, is slightly more relaxed. 整段不會被分開。
這個在 Elasticsearch (二) - 快速搭建與 Document 的建立、更新和刪除 中,介紹 Mapping 有提到過。如果是沒有先定義 Mapping 直接加入 Document 的話,Elasticsearch 會自動多加一個 Field,這個 Field 就會定義成 Keyword,也就是搜尋時要完全符合。
Language Analyzer (語言分析器)
語言分析器會根據指定的語言進行分詞,Elasticsearch 目前支援的還沒有中文。
同樣使用標準分析器範例所輸入的內容,經過英文的語言分析器後會產生 :3、semi、formal、name、impli、slightli、more、relax
使用內建分析器
首先先建立 6 個 Index 和 Type 並自訂 Mapping,分別指定每個欄位所要使用的分析器。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 PUT standard_analyzer POST standard_analyzer/_mapping/standard { "properties" : { "content" :{ "type" : "text" , "analyzer" : "standard" } } } PUT simple_analyzer POST simple_analyzer/_mapping/simple { "properties" : { "content" :{ "type" : "text" , "analyzer" : "simple" } } } PUT whitespace_analyzer POST whitespace_analyzer/_mapping/whitespace { "properties" : { "content" :{ "type" : "text" , "analyzer" : "whitespace" } } } PUT stop_analyzer POST stop_analyzer/_mapping/stop { "properties" : { "content" :{ "type" : "text" , "analyzer" : "stop" } } } PUT keyword_analyzer POST keyword_analyzer/_mapping/keyword { "properties" : { "content" :{ "type" : "text" , "analyzer" : "keyword" } } } PUT language_analyzer POST language_analyzer/_mapping/language { "properties" : { "content" :{ "type" : "text" , "analyzer" : "english" } } }
接著讓每個 Index 都建立一筆同樣的 Document。
1 2 3 4 5 6 7 8 9 10 11 12 13 POST _bulk { "create" : { "_index" : "standard_analyzer" , "_type" :"standard" , "_id" : 1 } } { "content" :"3. Semi-formal, as the name implies, is slightly more relaxed." } { "create" : { "_index" : "simple_analyzer" , "_type" :"simple" , "_id" : 2 } } { "content" :"3. Semi-formal, as the name implies, is slightly more relaxed." } { "create" : { "_index" : "whitespace_analyzer" , "_type" :"whitespace" , "_id" : 3 } } { "content" :"3. Semi-formal, as the name implies, is slightly more relaxed." } { "create" : { "_index" : "stop_analyzer" , "_type" :"stop" , "_id" : 4 } } { "content" :"3. Semi-formal, as the name implies, is slightly more relaxed." } { "create" : { "_index" : "keyword_analyzer" , "_type" :"keyword" , "_id" : 5 } } { "content" :"3. Semi-formal, as the name implies, is slightly more relaxed." } { "create" : { "_index" : "language_analyzer" , "_type" :"language" , "_id" : 6 } } { "content" :"3. Semi-formal, as the name implies, is slightly more relaxed." }
查看分析結果
_analyze
_analyze 可以直接看到分詞的結果。這裡以標準分析器為例子。
1 2 3 4 5 GET standard_analyzer/_analyze { "field" : "content" , "text" : "3. Semi-formal, as the name implies, is slightly more relaxed." }
分詞的結果如下,token 就是分詞後的每個單詞。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 { "tokens" : [ { "token" : "3" , "start_offset" : 0 , "end_offset" : 1 , "type" : "<NUM>" , "position" : 0 }, { "token" : "semi" , "start_offset" : 3 , "end_offset" : 7 , "type" : "<ALPHANUM>" , "position" : 1 }, { "token" : "formal" , "start_offset" : 8 , "end_offset" : 14 , "type" : "<ALPHANUM>" , "position" : 2 }, { "token" : "as" , "start_offset" : 16 , "end_offset" : 18 , "type" : "<ALPHANUM>" , "position" : 3 }, { "token" : "the" , "start_offset" : 19 , "end_offset" : 22 , "type" : "<ALPHANUM>" , "position" : 4 }, { "token" : "name" , "start_offset" : 23 , "end_offset" : 27 , "type" : "<ALPHANUM>" , "position" : 5 }, { "token" : "implies" , "start_offset" : 28 , "end_offset" : 35 , "type" : "<ALPHANUM>" , "position" : 6 }, { "token" : "is" , "start_offset" : 37 , "end_offset" : 39 , "type" : "<ALPHANUM>" , "position" : 7 }, { "token" : "slightly" , "start_offset" : 40 , "end_offset" : 48 , "type" : "<ALPHANUM>" , "position" : 8 }, { "token" : "more" , "start_offset" : 49 , "end_offset" : 53 , "type" : "<ALPHANUM>" , "position" : 9 }, { "token" : "relaxed" , "start_offset" : 54 , "end_offset" : 61 , "type" : "<ALPHANUM>" , "position" : 10 } ] }
_termvectors
_termvectors 可以用來查看一個 Document 的單詞的訊息。
1 2 3 4 GET /standard_analyzer/standard/1/_termvectors { "fields" : ["content" ] }
下面是輸出的結果,在 term_vectors 的 terms 中就可以看到每個單詞的訊息。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 { "_index" : "standard_analyzer" , "_type" : "standard" , "_id" : "1" , "_version" : 3 , "found" : true , "took" : 16 , "term_vectors" : { "content" : { "field_statistics" : { "sum_doc_freq" : 11 , "doc_count" : 1 , "sum_ttf" : 11 }, "terms" : { "3" : { "term_freq" : 1 , "tokens" : [ { "position" : 0 , "start_offset" : 0 , "end_offset" : 1 } ] }, "as" : { "term_freq" : 1 , "tokens" : [ { "position" : 3 , "start_offset" : 16 , "end_offset" : 18 } ] }, "formal" : { "term_freq" : 1 , "tokens" : [ { "position" : 2 , "start_offset" : 8 , "end_offset" : 14 } ] }, "implies" : { "term_freq" : 1 , "tokens" : [ { "position" : 6 , "start_offset" : 28 , "end_offset" : 35 } ] }, "is" : { "term_freq" : 1 , "tokens" : [ { "position" : 7 , "start_offset" : 37 , "end_offset" : 39 } ] }, "more" : { "term_freq" : 1 , "tokens" : [ { "position" : 9 , "start_offset" : 49 , "end_offset" : 53 } ] }, "name" : { "term_freq" : 1 , "tokens" : [ { "position" : 5 , "start_offset" : 23 , "end_offset" : 27 } ] }, "relaxed" : { "term_freq" : 1 , "tokens" : [ { "position" : 10 , "start_offset" : 54 , "end_offset" : 61 } ] }, "semi" : { "term_freq" : 1 , "tokens" : [ { "position" : 1 , "start_offset" : 3 , "end_offset" : 7 } ] }, "slightly" : { "term_freq" : 1 , "tokens" : [ { "position" : 8 , "start_offset" : 40 , "end_offset" : 48 } ] }, "the" : { "term_freq" : 1 , "tokens" : [ { "position" : 4 , "start_offset" : 19 , "end_offset" : 22 } ] } } } } }
_analyze v.s _termvectors
以上兩個查看分析器結果的 API 差別在於 _analyze 是在建立前先查看使用這個分析器所做出的分詞結果會是甚麼。而 _termvectors 是用來顯示分詞的訊息,所以已經是寫入 Document 經過分析器做好的結果了,可以用在建好之後查看分詞結果。
開始搜尋
以下以幾種不同的搜尋內容來看各個分析器所造成的影響。
1. 搜尋 semi
1 2 3 4 5 6 7 8 GET _search { "query" :{ "term" :{ "content" : "semi" } } }
下面是搜尋的結果,可以看到搜尋到了 simple、standard、language、stop 四個分析器的結果。因為這四個分析器在進行分詞時,會把 semi 分成單詞存在反向索引中,所以可以被找到。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 { "took" : 1 , "timed_out" : false , "_shards" : { "total" : 51 , "successful" : 51 , "skipped" : 0 , "failed" : 0 }, "hits" : { "total" : 4 , "max_score" : 0.2876821 , "hits" : [ { "_index" : "language_analyzer" , "_type" : "language" , "_id" : "6" , "_score" : 0.2876821 , "_source" : { "content" : "3. Semi-formal, as the name implies, is slightly more relaxed." } }, { "_index" : "simple_analyzer" , "_type" : "simple" , "_id" : "2" , "_score" : 0.2876821 , "_source" : { "content" : "3. Semi-formal, as the name implies, is slightly more relaxed." } }, { "_index" : "stop_analyzer" , "_type" : "stop" , "_id" : "4" , "_score" : 0.2876821 , "_source" : { "content" : "3. Semi-formal, as the name implies, is slightly more relaxed." } }, { "_index" : "standard_analyzer" , "_type" : "standard" , "_id" : "1" , "_score" : 0.2876821 , "_source" : { "content" : "3. Semi-formal, as the name implies, is slightly more relaxed." } } ] } }
2. 搜尋 Semi-formal,
1 2 3 4 5 6 7 8 GET _search { "query" :{ "term" :{ "content" : "Semi-formal," } } }
下面是搜尋的結果,可以看到只找到了 whitespace 這個分析器的結果。這是因為 whitespace 只會在空格處做分詞,所以 Semi-formal, 會被劃分為一個單詞。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 { "took" : 0 , "timed_out" : false , "_shards" : { "total" : 36 , "successful" : 36 , "skipped" : 0 , "failed" : 0 }, "hits" : { "total" : 1 , "max_score" : 0.2876821 , "hits" : [ { "_index" : "whitespace_analyzer" , "_type" : "whitespace" , "_id" : "3" , "_score" : 0.2876821 , "_source" : { "content" : "3. Semi-formal, as the name implies, is slightly more relaxed." } } ] } }
3. 搜尋 is
1 2 3 4 5 6 7 8 GET _search { "query" :{ "term" :{ "content" : "is" } } }
下面是輸出的結果,可以看到搜尋到了 simple、standard、whitespace 三個分析器的結果。其他三個因為都沒有提取 is 這個單詞作為索引,所以會找不到。像是 stop 分析器就把 is 過濾掉了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 { "took" : 0 , "timed_out" : false , "_shards" : { "total" : 51 , "successful" : 51 , "skipped" : 0 , "failed" : 0 }, "hits" : { "total" : 3 , "max_score" : 0.2876821 , "hits" : [ { "_index" : "simple_analyzer" , "_type" : "simple" , "_id" : "2" , "_score" : 0.2876821 , "_source" : { "content" : "3. Semi-formal, as the name implies, is slightly more relaxed." } }, { "_index" : "standard_analyzer" , "_type" : "standard" , "_id" : "1" , "_score" : 0.2876821 , "_source" : { "content" : "3. Semi-formal, as the name implies, is slightly more relaxed." } }, { "_index" : "whitespace_analyzer" , "_type" : "whitespace" , "_id" : "3" , "_score" : 0.2876821 , "_source" : { "content" : "3. Semi-formal, as the name implies, is slightly more relaxed." } } ] } }
4. 搜尋 3. Semi-formal, as the name implies, is slightly more relaxed.
1 2 3 4 5 6 7 8 GET _search { "query" :{ "term" :{ "content" : "3. Semi-formal, as the name implies, is slightly more relaxed." } } }
下面是輸出的結果,可以看到只找到了 keyword 分析器的結果,因為 keyword 不會進行分詞。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 { "took" : 0 , "timed_out" : false , "_shards" : { "total" : 51 , "successful" : 51 , "skipped" : 0 , "failed" : 0 }, "hits" : { "total" : 1 , "max_score" : 0.2876821 , "hits" : [ { "_index" : "keyword_analyzer" , "_type" : "keyword" , "_id" : "5" , "_score" : 0.2876821 , "_source" : { "content" : "3. Semi-formal, as the name implies, is slightly more relaxed." } } ] } }
Summary
本篇介紹了分析器的概念以及 Elasticsearch 內建的一些分析器,如果想要更了解這些分析器更詳細的使用請參考 Elasticsearch 官網 。
參考
[1] Elasticsearch當中的分析器-Analyzer 在Elasticsearch中查詢Term Vectors詞條向量信息 掌握 analyze API,一舉搞定 Elasticsearch 分詞難題 正則表達式單詞邊界和非單詞邊界 通過 Analyzer 進行分詞 Text analysis 認識 ElasticSearch Analyzer 分析器 Elasticsearch Analyzer 的內部機制 中英文停用詞(stop word)列表